neo4j的导入与导出
本文最后更新于:2025年5月27日 晚上
本文主要介绍neo4j的导入(import,load)和导出(export),基本是基于csv和dump文件格式。将会介绍在终端和使用apoc利用Cypher语言两种情况如何实现导入导出,同时也会大致讲讲所需的csv文件的格式。并且所有的导入导出操作都是在终端或neo4j浏览器界面,并未使用编程语言。
我的版本配置:
- 操作系统 :ubuntu22.04
- neo4j server:5.10.0社区版
- apoc-core :5.10.1(这是个neo4j插件,之后会讲到)
1. 终端下导入导出
(ubuntu ctrl +alt +T 打开终端)。
与neo4j相关的命令基本是以neo4j,neo4j-admin或者neo4j-admin
server开头,三者在后面添加
-h都可以查看其帮助文档。
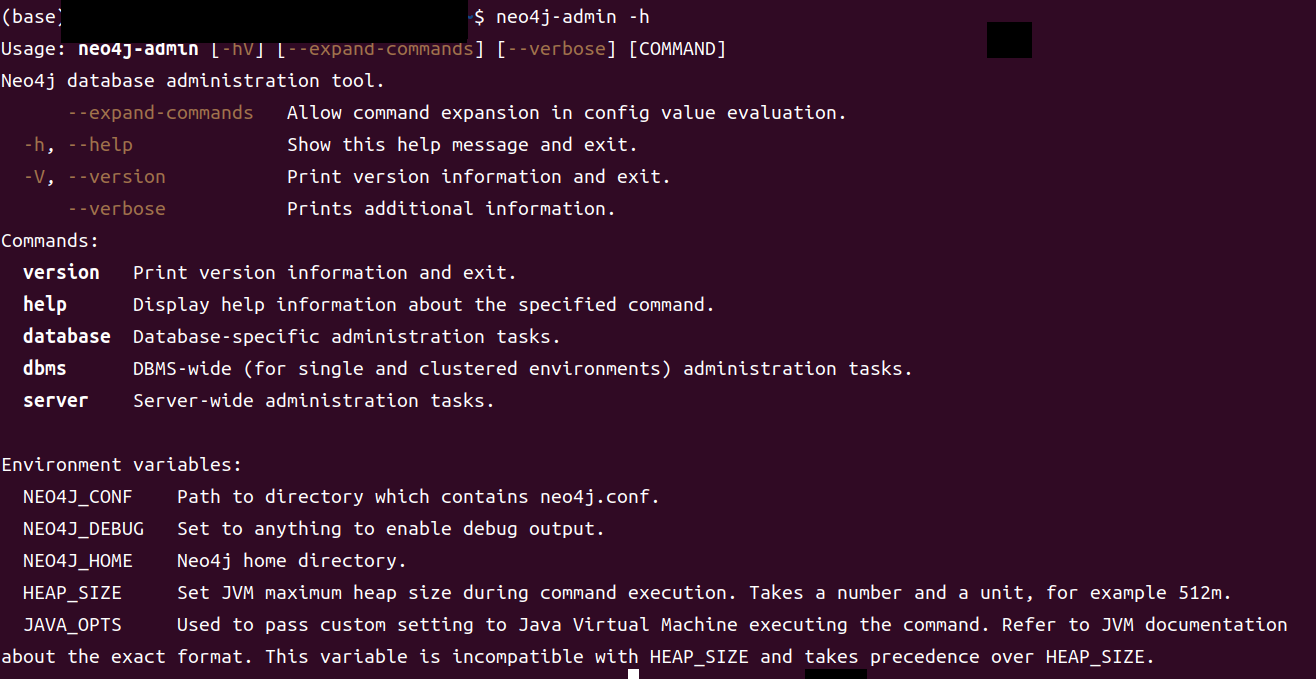
而我们需要的命令就是neo4j-admin database
我们使用
neo4j-admin database -h来查看neo4j-admin
database的使用方法。
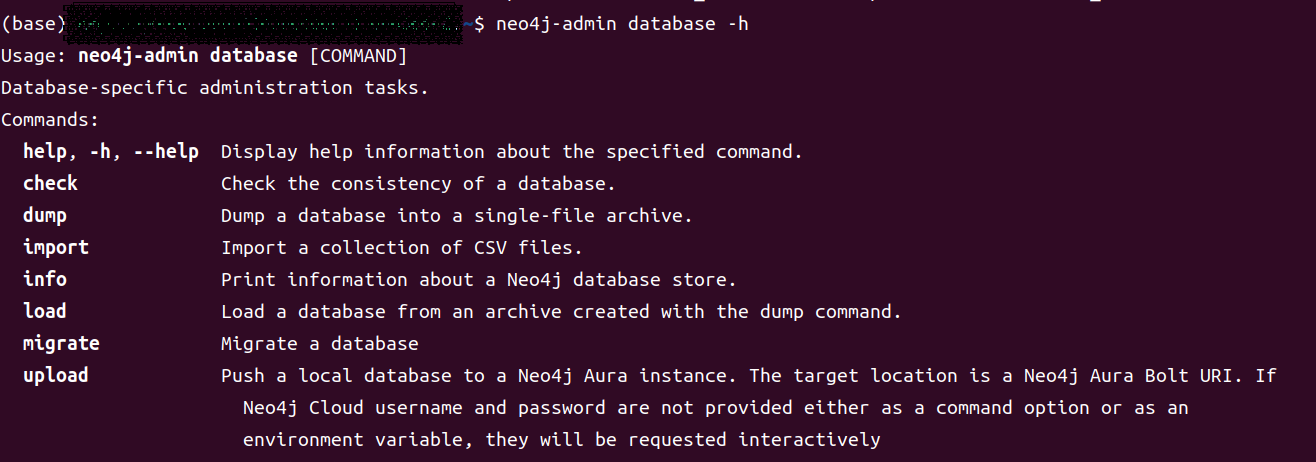
而我们要用的就是dump,load,import
dump
# 其中<>是必填选项其余的[]是非必填
# 可以使用neo4j-admin database dump -h查看各参数详细信息
# 效果是将neo4j的数据导出为一个dump文件,或者一个标准输出流进入类似load的命令
neo4j-admin database dump [-h] [--expand-commands]
[--verbose] [--overwrite-destination[=true|false]]
[--additional-config=<file>]
[--to-path=<path> | --to-stdout]
<database>
# --verbose: 加上后会在执行过程中输出详细的过程,方便了解其过程查看可能的错误点
# --overwrite-destination: 如果做后dump文件位置存在同名文件,是否覆盖,默认是false
# --to-path=<path>: 指定输出文件夹地址。注意!path必须为文件夹地址
# --to-stdout: 让输出成为标准输出流而不是一个dump文件
其中,如果你命令中既没有 --to-path也没有
--to-stdout,那么,它将会采用Configuration文件(各操作系统下的neo4j默认文件地址)中的
server.directories.dumps.root设置。
该设置值是一个文件路径,指dump文件存放的地址。
如果是相对路径,则是以
neo4j主目录/data/为基准的相对路径。例如
server.directories.dumps.root的默认值就是dumps,即如果你命令中既没有
--to-path也没有 --to-stdout,该命令将会在
neo4j主目录/data/dumps/ 下生成一个dump文件。
如果使用
neo4j-admin database dump来导出数据,要确保neo4j数据库处于stop状态
neo4j status查看当前neo4j运行状态
load
load方法主要就是将dump导出的 dump文件 或者 标准输出流 中的数据重新导入neo4j数据库中。所以,load+dump就可以实现neo4j的离线备份。
# load和dump的Options大同小异,
# 同样的,如果既没有--from-path,又没有--from-stdin,会采用server.directories.dumps.root
neo4j-admin database load [-h] [--expand-commands] [--info] [--verbose]
[--overwrite-destination[=true|false]]
[--additional-config=<file>] [--from-path=<path> | --from-stdin] <database>
# 有一个特殊的Option --info
# 如果你加上了这个选项,那么这个命令将不会将数据导入到neo4j数据库中
# 而是打印出这个数据的详细信息
# example
$ sudo neo4j-admin database load --from-path=/home/mmy intelligentmedicine.db --verbose
# 这里由于没选覆盖选项是新建一个数据库为intelligentmedicine.db
# 注意!path只要写到dump文件所在的文件夹就行,dump文件必须是<databasename>.dump
# 这里就是 intelligentmedicine.db.dump
与dump有些不同的是,load支持neo4j在线和离线状态的导入(付费版),但是两种都有要注意的地方
- 如果你打算覆盖原有的数据库,即–overwrite-destination设置成了true,那么你一定要先stop再执行load语句。
- 如果你打算新建一个数据库来存储你load的数据,那么无需离线,但是在load之后一定要create一个新的database。
- 社区版的neo4j不支持在线导入,只能关闭服务后导入(付费版没试,但是官方文档说load支持online,应该是指付费版)
- 社区版的load不支持增量导入,即要么覆盖要么新建数据库,不能在原有数据上加入。(付费版没试,不知道行不行)
ps: 社区版即免费的neo4j是只允许一个database,但是我们可以通过修改配置文件来实现多个database共存。但是也有缺点,每次切换数据库要restart,并且修改配置文件(这个简单,就加个#,删个#)。如果有空会分享一下。
import
The import command is used for loading large amounts of data from CSV files and supports full and incremental import into a running or stopped Neo4j DBMS.
上述是官方原话,但是测试发现社区版import只支持全量导入(full)并且只能离线,可能付费才能增量与在线导入。
# Usage: neo4j-admin database import [-h] [COMMAND]
# example
$ sudo neo4j-admin database import full --verbose --overwrite-destination=true --nodes /home/mmy/forimport_movie_nodes.csv --nodes /home/mmy/forimport_person_nodes.csv --relationships /home/mmy/forimport_rels.csv test.db
csv格式
import命令本身并没有什么好说的,我们来聊聊导入所需的csv文件格式。
a.存储nodes的csv文件
表头(header)
- 表头格式<name>:<field_type>
- label在表头并非必须,但是id一定要有
- 如果你不想让id加入你的属性值,可以不给它属性名(name),即把下表的movieid去掉。
| movieid:ID | year:int | :LABEL |
|---|---|---|
- 但是如果是增量或者批量导入,规则就有点复杂。主键的属性必须是标签与属性的结合
| uuid:ID{label:Person} | name:STRING{label:Person} | email:STRING |
|---|---|---|
在这里,uuid和name共同做主键区分节点,并且指定节点导入的label为Person
这一措施,主要是防止增量导入和批量导入时创建多个重复节点。
b.存储relationship的csv文件
表头
存储关系的表头必须包含:START_ID,:END_ID和:TYPE。其中前两个分别对应着关系的起始实体和结束实体的:ID,这就是为什么实体id是必须的。而:TYPE是指明这个关系的类型。
当然,关系也可以有属性,下图便是给关系增加了一个role属性
| :START_ID | :END_ID | :TYPE | role |
|---|---|---|---|
总结:在社区版,如果使用终端的方法,我们都无法实现在线操作与增量导入。而官方其实还有一种方法,使用Cypher命令load csv可以实现在线导入数据,csv文件地址可以是url形式。(https://neo4j.com/developer/guide-import-csv/)大家可以自行查看官方文档,有样例十分详细。
2. 利用apoc插件在线导出
apoc在neo4j 5.0之后分为apoc-core和apoc-extended两部分。前者是neo4j官方支持,后者由社区维护。
而由于apoc-extended最新只有5.9版本,作者neo4j为5.10.x,所以下文只使用了apoc-core。而extended在导入导出方面增加了可使用exel导入导出,可以导入html格式的数据,多样化导入csv文件。
apoc本质是一个插件,其内容十分丰富,远不止导入导出数据那么简单,大家如有需要可以查看上方的官方文档。
2.1 apoc的安装与配置
apoc默认状态下并未安装,所以我们要先安装。
apoc-core的安装
这个十分简单,在$NEO4J_HOME/labs文件夹(NEO4J_HOME表示neo4j主目录)中,你会找到一个jar文件。
将这个文件复制到$NEO4J_HOME/plugins文件夹下,apoc-core就算安装好了!
apoc-core配置
a.首先,找到你的neo4j配置文件neo4j.conf,neo4j各文件在各操作系统的地址官方文档给出了,链接在前文。
# 寻找并修改以下设置,推荐复制粘贴原有的然后去掉注释的#,再修改,方便之后还原默认设置
# 放宽apoc权限
dbms.security.procedures.unrestricted=apoc.*,algo.*
# 将apoc的全部都加入allowlist
dbms.security.procedures.allowlist=apoc.*,apoc.coll.*,apoc.load.*,gds.*b.之后在neo4j.conf同文件夹下创建一个apoc.conf文件,这个是apoc的配置文件,是要自己手动创建的。
# 加入下面三条设置
# 开启文件导出功能
apoc.export.file.enabled=true
# 开启文件导入功能
apoc.import.file.enabled=true
# 指明是否使用 neo4j.conf 指定的相关(导入导出涉及的)目录(默认就是 true)
apoc.import.file_use_neo4j_config=true
好了,接下来我们就可以使用apoc-core来导入导出了。
2.2 导出为csv文件
注意:这次启动方式不是neo4j start而是neo4j console,而只有这种启动才能顺利使用apoc
neo4j官方只能导出数据为dump或stream,而apoc让我们有了更多选择。
CALL apoc.export.csv.all("movies.csv", {})
// 短短一句,就可将你的全部nodes和relationships导出成一个csv文件
// 而由于我们在apoc.conf文件中第三条设置为TRUE,所以导出的文件将位于noe4j的import文件夹下
// 当然你也可以将设置改为false,并且给出文件的绝对路径,来自定义文件的导出位置
// 注意!!修改设置后noe4j可以在你电脑上任意位置输出文件,注意文件导出地址安全性,别写在不该写的地方!
CALL apoc.export.csv.all(null, {stream:true})
// 这样你的文件将导出成一个stream
MATCH (person:Person)
WHERE person.name STARTS WITH "L"
WITH collect(person) AS people
CALL apoc.export.csv.data(people, [], "movies-l.csv", {})
YIELD file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data
RETURN file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data
// 这样,我们就可以选择性的导出nodes
// 同时,我们注意到 apoc.export.csv.data第一个参数为nodes,第二个其实是relationships
// 而哪怕这里不导出关系,我们依旧要写一个[]保留位置,就和config参数的{}一样
MATCH (person:Person)-[actedIn:ACTED_IN]->(movie:Movie)
WITH collect(DISTINCT person) AS people, collect(DISTINCT movie) AS movies, collect(actedIn) AS actedInRels
CALL apoc.export.csv.data(people + movies, actedInRels, "movies-actedIn.csv", {})
YIELD file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data
RETURN file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data
// 我们选择性的导出了nodes和relationships
WITH "MATCH path = (person:Person)-[:DIRECTED]->(movie)
RETURN person.name AS name, person.born AS born,
movie.title AS title, movie.tagline AS tagline, movie.released AS released" AS query
CALL apoc.export.csv.query(query, "movies-directed.csv", {})
YIELD file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data
RETURN file, source, format, nodes, relationships, properties, time, rows, batchSize, batches, done, data;
//这是一个与之前不同的方法,在这里我们传入的不是nodes或relationships,而是一个语句,这样子看上去简单多了
大家或许注意到了,上述许多语句{}中的内容不是stream:true就是空的,其实,这里面可以设置很多配置
如下所示:
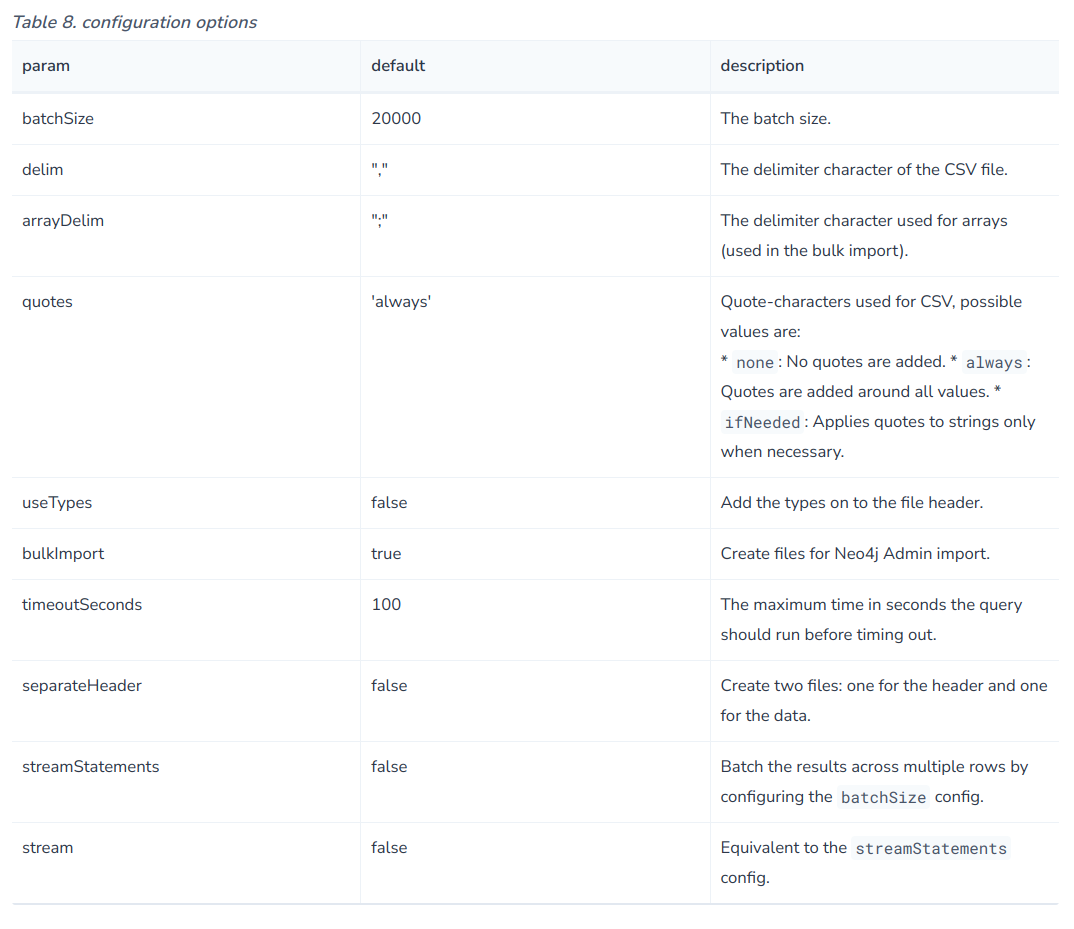
但是,其中的bulkImport设置只有在all和graph情况下才能生效:

2.3导出为json文件
// 基本与csv相同
CALL apoc.export.json.all("all.json",{useTypes:true})
// useTypes参数表明输出时是否表明type类型是node还是relationship// out
{"type":"node","id":"0","labels":["User"],"properties":{"born":"2015-07-04T19:32:24","name":"Adam","place":{"crs":"wgs-84","latitude":13.1,"longitude":33.46789,"height":null},"age":42,"male":true,"kids":["Sam","Anna","Grace"]}}
{"type":"node","id":"1","labels":["User"],"properties":{"name":"Jim","age":42}}
{"type":"node","id":"2","labels":["User"],"properties":{"age":12}}
{"id":"0","type":"relationship","label":"KNOWS","properties":{"bffSince":"P5M1DT12H","since":1993},"start":{"id":"0","labels":["User"],"properties":{"born":"2015-07-04T19:32:24","name":"Adam","place":{"crs":"wgs-84","latitude":13.1,"longitude":33.46789,"height":null},"age":42,"male":true,"kids":["Sam","Anna","Grace"]}},"end":{"id":"1","labels":["User"],"properties":{"name":"Jim","age":42}}}
2.4导出为Cypher语句
CALL apoc.export.cypher.schema()
YIELD format, time, cypherStatements
RETURN format, time, cypherStatements;
// 也与csv大同小异,多了一个schema,这个就支持导出索引以及所有的限制条件的建立,而不仅仅是一些数据
2.5导出为graphml文件
The export GraphML procedures export data into a format that’s used by other tools like Gephi and CytoScape to read graph data.
主要是导出给Gephi 使用
// example
call apoc.export.graphml.query('MATCH (start:Foo)-[:KNOWS]->(:Bar) RETURN start', 'queryNodesFoo.graphml', {useTypes: true}); <!-- out -->
<?xml version='1.0' encoding='UTF-8'?>
<graphml xmlns="http://graphml.graphdrawing.org/xmlns" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://graphml.graphdrawing.org/xmlns http://graphml.graphdrawing.org/xmlns/1.0/graphml.xsd">
<key id="born" for="node" attr.name="born" attr.type="string"/>
<key id="name" for="node" attr.name="name" attr.type="string"/>
<key id="place" for="node" attr.name="place" attr.type="string"/>
<key id="labels" for="node" attr.name="labels" attr.type="string"/>
<graph id="G" edgedefault="directed">
<node id="n0" labels=":Foo:Foo0:Foo2"><data key="labels">:Foo:Foo0:Foo2</data><data key="born">2018-10-10</data><data key="name">foo</data><data key="place">{"crs":"wgs-84-3d","latitude":12.78,"longitude":56.7,"height":100.0}</data></node>
<node id="n3" labels=":Foo"><data key="labels">:Foo</data><data key="name">zzz</data></node>
<node id="n5" labels=":Foo"><data key="labels">:Foo</data><data key="name">aaa</data></node>
</graph>
</graphml>
apoc-extended 的导入还支持导入excel文件,但是不能是最新的5.10版本的neo4j。
3.利用apoc在线导入
3.1 从Web-APIs导入
As
apoc.import.file.use_neo4j_configis enabled, the procedures check whether file system access is allowed and possibly constrained to a specific directory by reading the two configuration parametersdbms.security.allow_csv_import_from_file_urlsandserver.directories.importrespectively. If you want to remove these constraints please setapoc.import.file.use_neo4j_config=false
如果
apoc.import.file.use_neo4j_config设置为true,文件写入可能会有所限制。可以设为false,但是要注意安全性。
// example,可以用url导入数据
CALL apoc.load.xml('http://example.com/test.xml', ['xPath'], [config]) YIELD value as doc CREATE (p:Person) SET p.name = doc.name
// 还可以从google cloud storage导入数据导入数据,但是要另外加一堆插件
3.2 load csv文件
这是需安装apoc-extended,比较实用,提一下。
- provide a line number
- provide both a map and a list representation of each line
- automatic data conversion (including split into arrays)
- option to keep the original string formatted values
- ignoring fields (makes it easier to assign a full line as properties)
- headerless files
- replacing certain values with null
上述便是apoc在load csv方面相对官方方法的改进
CALL apoc.load.csv('test.csv')
YIELD lineNo, map, list
RETURN *;
CALL apoc.load.csv({url}) yield map as row return row
CREATE (p:Person) SET p = row
多种配置任你选择:
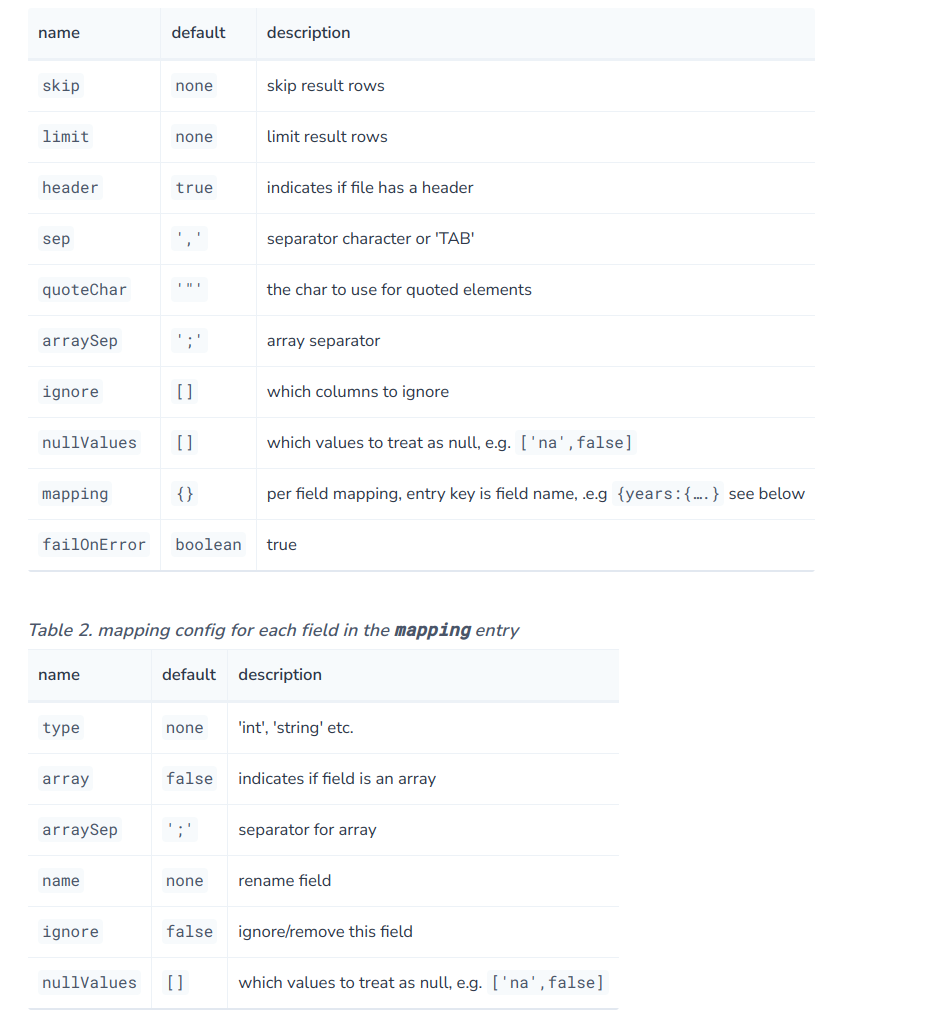
CALL apoc.load.csv('test.csv', {skip:1, limit:1, header:true, ignore:['name'],
mapping:{
age: {type:'int'},
beverage: {array:true, arraySep:';', name:'drinks'}
}
})
YIELD lineNo, map, list
RETURN *;
// 其中地一个设置是针对文件的,第二个是针对读入的map
3.3 导入excel文件
这个是在安装apoc-extended基础下的,因为比较常用了,稍微提一下。但是因为支持该功能的文件太大了,所以apoc将其分离出去了,你需另外下载支持文件安装到plugins文件夹下。
For loading XLS we’re using the Apache POI library, which works well with old and new Excel formats, but is quite large. That’s why we decided not to include it into the apoc jar, but make it an optional dependency.
These dependencies are included in apoc-xls-dependencies-5.9.0-all.jar, which can be downloaded from the releases page. Once that file is downloaded, it should be placed in the
pluginsdirectory and the Neo4j Server restarted.Alternatively, you can download these jars from Maven Repository (putting them into
pluginsdirectory as well):For XLS files:
Additional for XLSX files:
// 同样简单明了
CALL apoc.load.xls({url}, {Name of sheet}, {config})
// 这里是'Full',整个文件全导入
CALL apoc.load.xls('file:///path/to/file.xls','Full',{mapping:{Integer:{type:'int'}, Array:{type:'int',array:true,arraySep:';'}}})
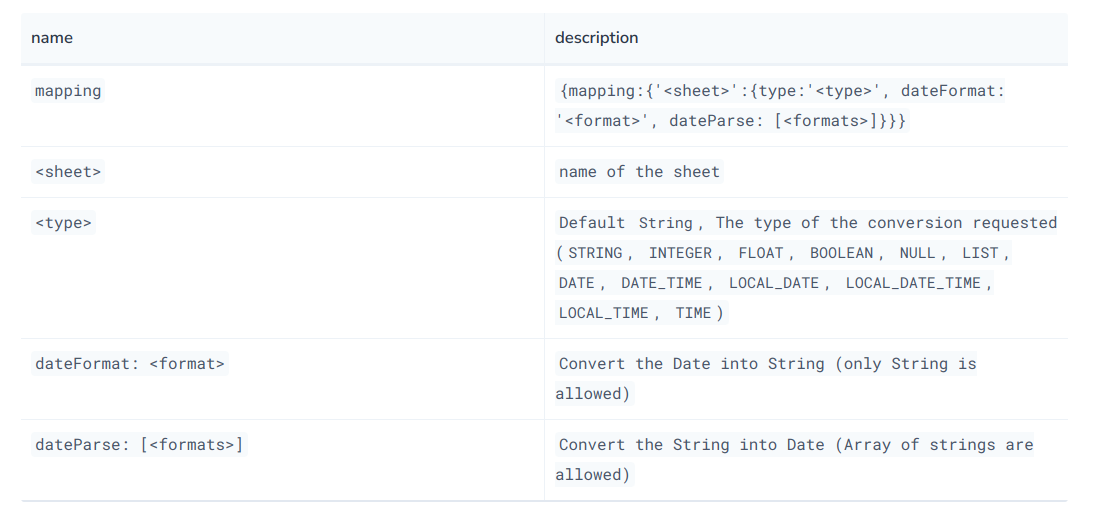
// 至于导入后再怎么处理,其实就和导入csv后处理一样,官方文档看一下load csv相关文档即可config格式如下:
3.4 import csv文件
在apoc中,load和import其实是有一定区别的。
load是导入neo4j类似缓存中,可以做后续操作后再导入neo4j数据库中(当然,也可以不导入)
import是运行后就将数据存储入数据库中。
而在apoc-core官方文档中提到:只要是满足apoc的csv文件格式规则的,就可以使用
apoc.import.csv来导入数据,但是对于大型数据,他们更推荐官方的import方式。(就是上文提到的终端下的
neo4j-admin database import)
// apoc.import.csv(<nodes>, <relationships>, <config>)
// 其中nodes和relationships都是以list,即[]的形式传入
// 而list中单个node或relationship又以map的形式传入
// <nodes>: [{fileName: 'file:/persons.csv', labels: ['Teacher','Student']}]
// 传入文件,以及文件中所含的标签
// <relationships>: [{fileName:'file:/...',type:'KNOWS'}]
// 传入文件以及关系的type
//注意!!map的关键字(key)一定要严格按照上方写,fileName写成filename就会出错!!
// example
CALL apoc.import.csv(
[{fileName: 'file:/persons.csv', labels: ['Person']}],
[{fileName: 'file:/knows.csv', type: 'KNOWS'}],
{delimiter: '|', arrayDelimiter: ',', stringIds: false}
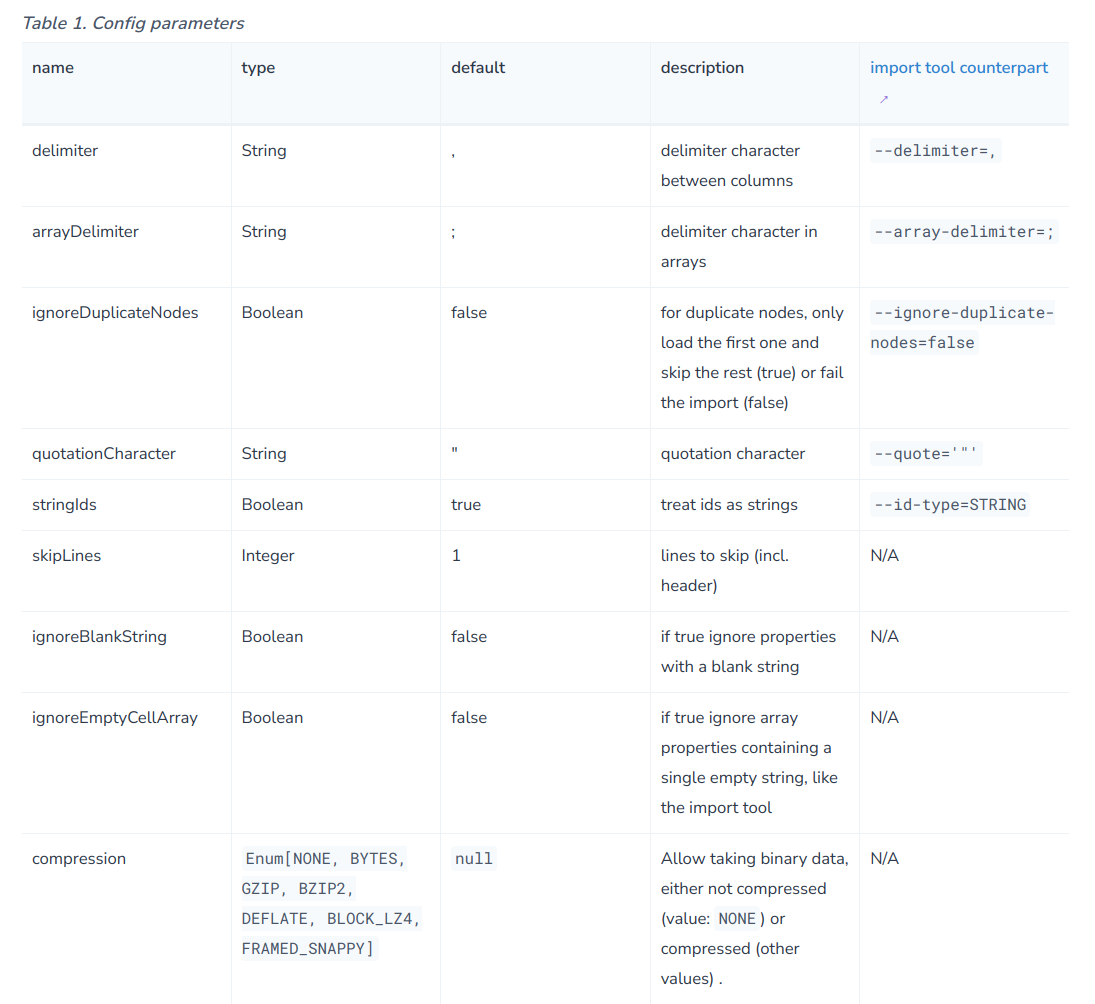
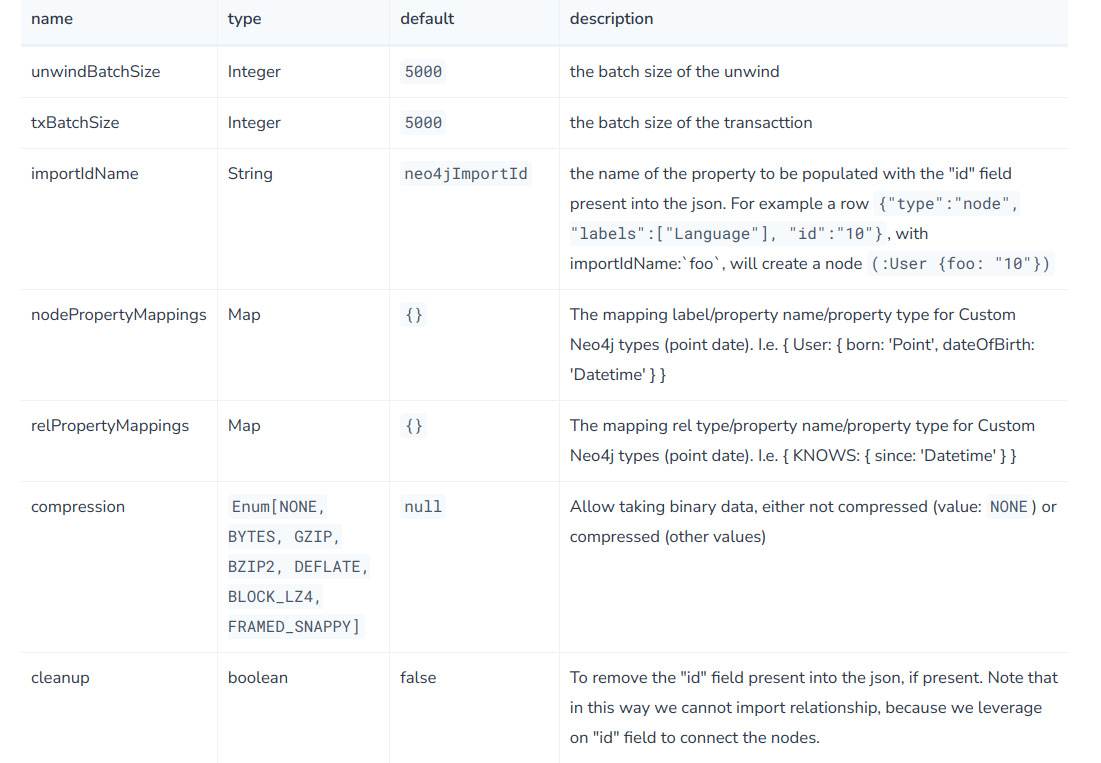
)config中可选配置如下:
3.5 导入json文件
- apoc.load.json()
apoc.load.json(urlOrKeyOrBinary :: ANY?, path = :: STRING?, config = {} :: MAP?) :: (value :: MAP?)
// apoc.load.json
// 其中的path可以使用jsonPath,来指定导入内容
//example
CALL apoc.load.json("file:///person.json")
YIELD value
MERGE (p:Person {name: value.name})
SET p.age = value.age
WITH p, value
UNWIND value.children AS child
MERGE (c:Person {name: child})
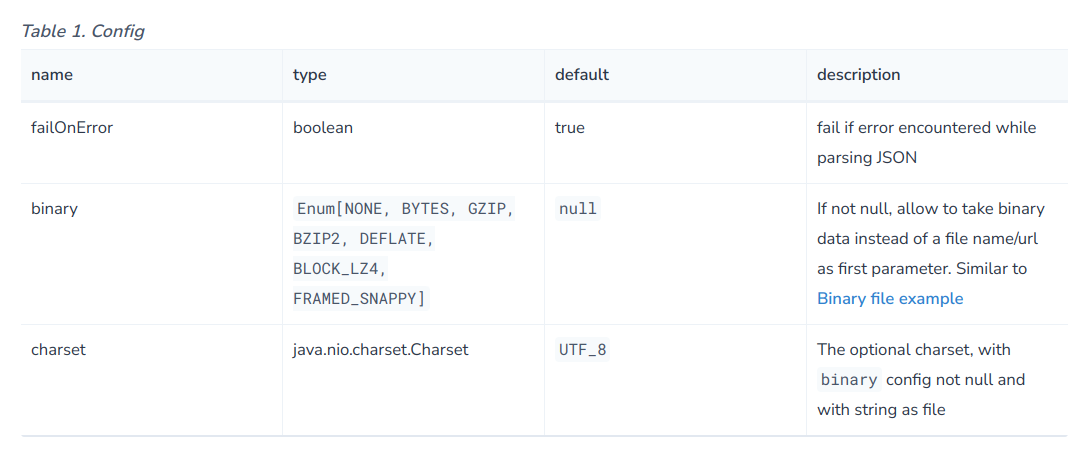
MERGE (c)-[:CHILD_OF]->(p);config:
- apoc.import.json()
apoc.import.json(urlOrBinaryFile Any, config Map<String, Any>)
// import和load不一样,load后是要将数据进行后续操作,不一定保存到数据库中
// import的作用就是将数据导入
// 而通过观察import的signature我们可以发现,它不接受path参数,
// 这意味着import只能整个文件导入,那么这个文件要求保持一定格式规范,最好是通过apoc导出的json文件导入的json文件样例:
{"type":"node","id":"0","labels":["User"],"properties":{"born":"2015-07-04T19:32:24","name":"Adam","place":{"crs":"wgs-84","latitude":13.1,"longitude":33.46789,"height":null},"age":42,"male":true,"kids":["Sam","Anna","Grace"]}}
{"type":"node","id":"1","labels":["User"],"properties":{"name":"Jim","age":42}}
{"type":"node","id":"2","labels":["User"],"properties":{"age":12}}
{"id":"0","type":"relationship","label":"KNOWS","properties":{"bffSince":"P5M1DT12H","since":1993},"start":{"id":"0","labels":["User"],"properties":{"born":"2015-07-04T19:32:24","name":"Adam","place":{"crs":"wgs-84","latitude":13.1,"longitude":33.46789,"height":null},"age":42,"male":true,"kids":["Sam","Anna","Grace"]}},"end":{"id":"1","labels":["User"],"properties":{"name":"Jim","age":42}}}config:

apoc-core还支持导入xml文件和graphml,与前面的json等基本一致,这里就不介绍了,大家可以看一下官方文档。
4. 复制数据库秘籍——复制文件夹大法
当我们要将海量的数据从一个neo4j数据库导入另一台计算机的neo4j数据库时,如果采用上述的办法,或许要等非常长的时间。此时我们就可以直接复制文件。
具体步骤如下:
- 假设我们被复制的数据库的名字为Data.db。
- 打开需要复制数据的电脑(即数据源)的 neo4j主目录/data/ ,在其目录下有两个文件夹,databases和transactions。在这两个数据夹下各有一个Data.db文件夹,这就是neo4j的Data.db数据库存储的数据。
- 拷贝这两个文件夹到需要导入的电脑,放置在同样的目录下。注意!一定要放在同样的目录下,由于两个文件夹是同名的,所以注意别放错了地方。
- 新建database,我推荐是和被复制的数据库同名,即Data.db。这个我个人试过,肯定没问题。你也可以试试建一个myData.db,然后把那两个文件夹重命名为myData.db。
提示:可能会在复制粘贴文件夹时提示无权限修改或权限不足一类的,linux操作系统可以在终端中使用
sudo mv -i 所需复制的文件 目的地