SynFoC
本文最后更新于:2025年7月3日 上午
一、研究内容
1.半监督背景
由于带标注的医学影像十分稀缺,而训练数据集不足对于深度学习训练是极其致命的。因此,传统模型和基准模型(高泛化能力的大模型)进行半监督学习是医学影像进行分割的一个方法。
举个简单的例子,两个分割模型:Unet和MedSAM。前者是随机初始化的传统模型,后者是经过大量数据集训练的基准模型。前者通过有标签的少量数据进行监督训练。同时后者通过其已经具备的知识对无标注数据进行预测,生成一个伪标签标注。而生成的伪标签作为无标签数据进入Unet网络进行训练时的指导标准。通过这一系列的操作使得原本无标签数据也可以进入训练数据集进行训练,这大大弥补了训练数据不足的短板。
2.问题
而拿伪标签作真标签用十分依赖基准模型的能力,并且很可能存在一个问题:领域迁移。
基准模型追求泛化性,经过 海量 数据集训练,但是再海量也总是有限的。
医学影像与常规图像不同,常规图像类别较少,普遍没有太大的差异。医学影像则各色各样:核磁、超声、CT、X光等。这些还只是大类,内部还可细分,而哪怕细分后,依旧多种多样。拿B型超声图像举例,不同的扫描设备得到的图像区别极大,不同患者群体的超声图像也风格迥异,还有医生在扫描时的不同设备参数,扫描手法等等。
总之,医学影像是存在各种 域 ,同一个 域 中图像信息有共通之处,而不同 域 则会存在差异,而医学影像搜集的大量无标签数据可能来自各种不同的 域 (比如不同医生不同设备扫描的超声图像)。而在生成伪标签时,基准模型学习的 域 很有可能与无标签中的某些 域 差距很大,但是它坚定不移地拿之前 域 学到的知识应用于当前 域 。此时,很有可能会产生一个 高置信度错误预测 ,从而带偏学生模型。而半监督学习中有标签数据与无标签数据之间也可能存在 领域迁移 ,这也会对模型性能造成干扰。
3.解决
作者发现Unet这种传统模型网络虽然在前期需要MedSAM基准模型指导,但是随着训练不断完善,可以逐渐通过Unet来纠正基准模型的高置信度错误预测。
针对半监督中领域迁移问题,作者通过基准模型和传统模型协同训练优化半监督中的无标签数据训练,即前期基准模型主导后期传统模型参与辅助,提高医学影像分割效果。同时,作者也利用一致性与融合的方式处理有标签数据与无标签数据间和无标签数据内部的领域迁移。
个人理解作者主要利用两个核心处理该问题:融合 与 一致性正则化
二、方法
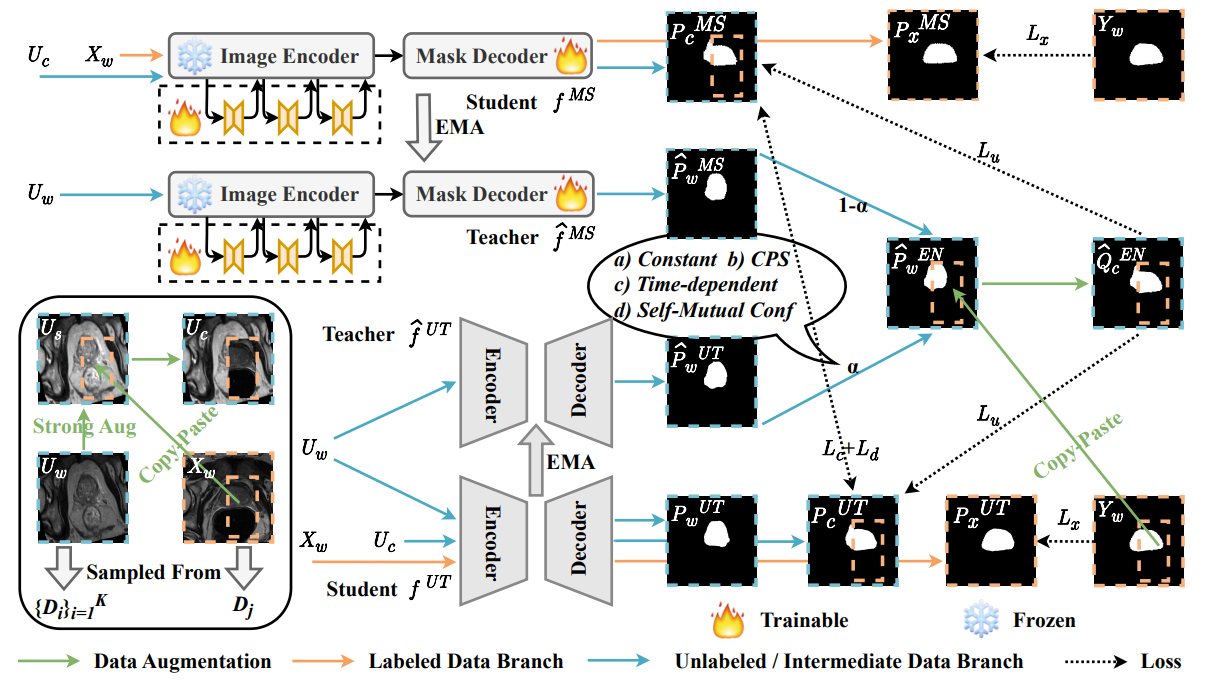
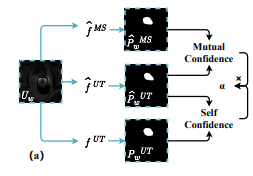
模型如图所示,重点在对教师模型生成的预测图的处理,与一系列损失函数的计算
U为无标签数据,X为有标签数据
Y是真正标注的标签,P和Q都是预测结果(P和Q的使用图像和论文公式有些不一致,主要看上下标)
s表示经过弱扰动,例如随机裁切,旋转,翻转等;w表示强扰动,例如亮度调整,对比度变化等
c是经过复制粘贴融合有标签数据与无标签数据生成的中间数据,后续会讲
ɑ是两个教师模型预测图融合时需要的权重,后续会讲
1.概述
整体结构由四个模型组成,一对Unet的教师-学生模型,一对MedSAM的教师-学生模型。
流程大致如下:
将强扰动无标签数据与有弱扰动有标签数据融合生成一张中间数据
MedSAM的学生模型接收中间数据和弱扰动无标签数据各自生成一张预测结果
UNET的学生模型接收中间数据,弱扰动无标签数据和弱扰动有标签数据各自生成一张预测结果
两个教师模型接收弱扰动的无标签数据,各自生成一张预测结果
通过UNET的学生模型,UNET的教师模型与MedSAM的教师模型三者结果计算出权重ɑ
两个教师模型通过ɑ加权融合两者的预测结果获得一张无标签数据预测图
将上步得到的无标签数据预测图与弱扰动有标签真实标签融合,得到中间数据的伪标签
根据上述各种预测结果与伪标签对学生模型进行梯度反向传播
教师模型由 Exponential Moving Average(EMA) 从学生模型更新
学生模型的损失有三大类:
- 小部分带标签的数据进行损失函数计算 Lx
- 大部分无标签数据由两个教师模型共同生成一个中间数据伪标签,由其指导在高置信度预测区域计算损失函数 Lu
- 对两个学生模型预测一致区域计算香农熵(损失 Lc )来加强一致区域,对有歧义的区域进行均方误差计算(损失 Ld )尽可能减少歧义
以上只是概述,部分细节请阅读原文,例如损失函数的实现与融合方法等
2.精华
[!note]
个人选择
2.1中间数据
模型中引人注目的下标c代表的中间数据,利用这种办法减少有标签数据与无标签数据间的领域迁移,帮助学生模型更好学习医学影像深层知识而不是仪器参数等带来的风格区别。
该数据由强扰动无标签数据与有弱扰动有标签数据融合生成
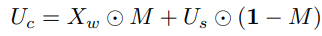
数据融合方式十分简单,上图公式所示,即裁切一部分有标签数据复制到无标签数据对应区域进行覆盖。
关于区域的选取论文中没有明确指出,阅读源代码发现是随机选取:
def obtain_cutmix_box(img_size, p=0.5, size_min=0.02, size_max=0.4, ratio_1=0.3, ratio_2=1/0.3):
mask = torch.zeros(img_size, img_size).cuda()
if random.random() > p:
return mask
size = np.random.uniform(size_min, size_max) * img_size * img_size
while True:
ratio = np.random.uniform(ratio_1, ratio_2)
cutmix_w = int(np.sqrt(size / ratio))
cutmix_h = int(np.sqrt(size * ratio))
x = np.random.randint(0, img_size)
y = np.random.randint(0, img_size)
if x + cutmix_w <= img_size and y + cutmix_h <= img_size:
break
mask[y:y + cutmix_h, x:x + cutmix_w] = 1
return mask也有细节部分,例如用ratio去限制区域的长宽比防止过于细长的选取出现,通过
size_min 和 size_max 控制选取的面积
标签融合即掩码融合与数据融合一样,用同样的区域选取真实标签复制粘贴到教师模型获得的伪标签上
2.2伪标签的融合
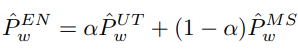
之前提到两个教师模型通过权重ɑ将两份伪标签融合为一张伪标签。
权重的选取至关重要,作者发现基准模型MedSAM可以在前期指导传统模型UNET,但是由于领域偏移容易出现高置信度错误预测,而随着UNET的完善,可以对MedSAM犯下的该错误进行一定的纠正。
因此,权重应该是一个动态变化的,在前期由MedSAM主导,ɑ很小,而随着UNET越来越可靠,ɑ逐渐变大。
所以,权重ɑ的大小与教师模型UNET是否可靠密切相关,而对于可靠性的量化作者使用 一致性 。
作者认为,对于一张图的预测结果,如果教师UNET足够可靠,那么他应该与学生UNET与教师MedSAM的预测较为统一,差异较小。
依据该原则,如下图所示,作者分别统计教师UNET与学生UNET和教师MedSAM的预测结果一致性,分别得到两个指标 Self-Confidence 和 Mutual-Confidence ,再将两者相乘得到权重ɑ。
2.3学生间的一致性正则化
作者的 协同 还体现在两个学生模型间互助训练。
在无标签数据预测中,对于两个学生预测 意见一致 的区域进行 香农熵 的计算,通过该指标引导他们在一致的方面更加团结。
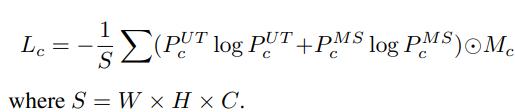
而对于预测 存在歧义 的区域通过 均方误差 进行协商调整,减少歧义。
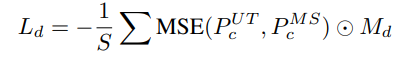
其中 Mc 和 Md 分别代表一致区域与歧义区域的 布尔矩阵 ,通过 Hadamard product 实现区域选取操作。
三、实验
作者进行了大量的对照与消融实验,该部分理解简单不是本文的重点,故简单摘取部分介绍
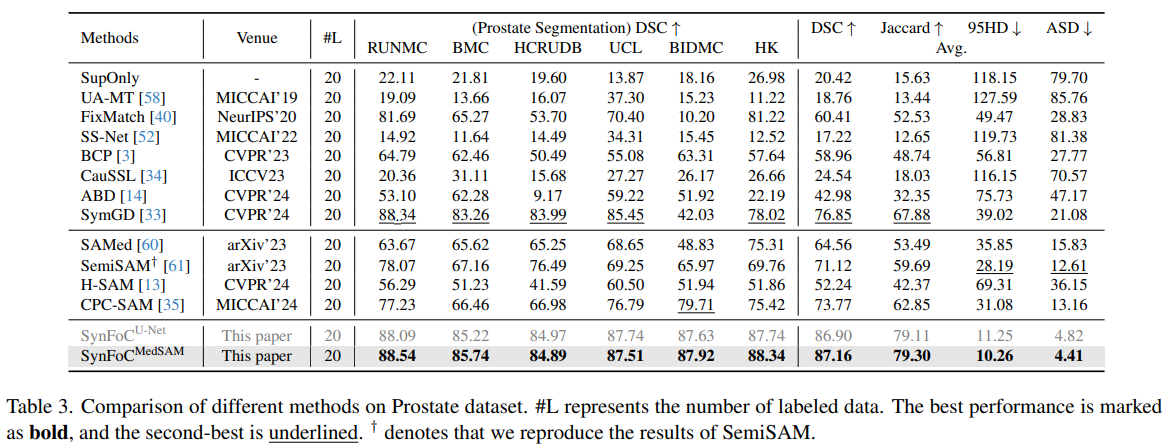
在前列腺数据集上对比实验,最后两行分别是拿学生UNET和学生MedSAM测试结果
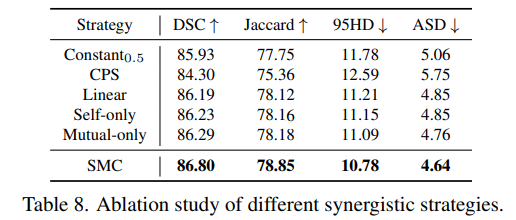
对于权重ɑ设计的消融实验
四、?
个人觉得阅读时的思考十分重要,而本人目前学识尚浅,但是依旧希望通过记录提醒自己保持探索思考,便有了该节
以下内容十分浅显乏味甚至错误,不读也罢
作者主要围绕 医学影像半监督 中的 领域迁移 问题,利用 融合 和 一致性正则化 两个核心内容应对。
优点: 对无标签数据风格万千,差异较大问题进行改善
缺点: 整体上应用了四个模型,损失函数复杂,标签多次处理,虽然只有两个通过反向传播学习,并且 MedSAM 通过 LoRa 优化训练,整体训练成本可能还是不低
问题:
- 阅读论文与源码发现对于中间数据生成是通过复制粘贴,但是由于覆盖的原因加上代码中似乎并没有相应判断,可能会将有标签数据的掩码标签的全黑部分覆盖掉无标签数据的待检测部分,导致最后中间数据中没有待检测区域,掩码为全黑。可以通过控制框选区域对应的真实标签的待检测区域(白色掩码区域)在选取的占比优化。
- 权重ɑ通过两个 Confidence 相乘获得,对于 Mutual-Confidence ,该值小可能是教师UNET不够可靠,但是也可能是教师MedSAM出现了高置信度预测错误,而后者不正是更需要UNET站出来的情况吗?